Model debugging¶
Warning
This is a beta feature. It does not support the full language yet and it might not work as expected. Currently known limitations:
lists and dicts not supported
string interpolation not supported
constructor kwargs not supported
plugins not supported
conditionals not supported
for loops not supported
boolean operations not supported
explicit index lookups not supported
only double assignment, exceeding relation arity and incomplete instance errors are supported
Support for the listed language features will be added gradually.
The inmanta DSL is essentially a data flow oriented language. As a model developer you never
explicitly manipulate control flow. Instead you declare data flow: the statement x = y
for example declares that the data in y should flow towards x. Even dynamic statements
such as implementations and for loops do not explicitly manipulate control flow. They too can be
interpreted as data flow declarations.
Because of this property conventional debugging methods such as inspecting a stack trace are not directly applicable to the inmanta language. A stack trace is meant to give the developer insight in the part of the control flow that led to the error. Extending this idea to the inmanta DSL leads to the concept of a data trace. Since the language is data flow oriented, a trace of the flow to some erroneous part of the configuration model gives the developer insight in the cause of the error.
Additionally, a root cause analysis will be done on any incomplete instances and only those root causes will be reported.
The first section, Enabling the data trace describes how to enable these two tools. The tools themselves are described in the sections Interpreting the data trace and Root cause analysis respectively. An example use case is shown in Usage example, and the final section, Graphic visualization, shortly describes a graphic representation of the data flow.
Enabling the data trace¶
To show a data trace when an error occurs, compile the model with the --experimental-data-trace
flag. For example:
1x = 1
2x = 2
Compiling with inmanta compile --experimental-data-trace results in
inmanta.ast.DoubleSetException: value set twice:
old value: 1
set at ./main.cf:1
new value: 2
set at ./main.cf:2
data trace:
x
├── 1
│ SET BY `x = 1`
│ AT ./main.cf:1
└── 2
SET BY `x = 2`
AT ./main.cf:2
(reported in x = 2 (./main.cf:2))
Interpreting the data trace¶
Let’s have another look at the data trace for the model above:
1x
2├── 1
3│ SET BY `x = 1`
4│ AT ./main.cf:1
5└── 2
6 SET BY `x = 2`
7 AT ./main.cf:2
Line 1 shows the variable where the error occurred. A tree departs from there with branches going to
lines 2 and 5 respectively. These branches indicate the data flow to x. In this case line 2 indicates
x has been assigned the literal 1 by the statement x = 1 at main.cf:1 and the literal
2 by the statement x = 2 at main.cf:2.
Now let’s go one step further and add an assignment to another variable.
1x = 0
2x = y
3y = 1
1x
2├── y
3│ SET BY `x = y`
4│ AT ./variable-assignment.cf:2
5│ └── 1
6│ SET BY `y = 1`
7│ AT ./variable-assignment.cf:3
8└── 0
9 SET BY `x = 0`
10 AT ./variable-assignment.cf:1
As before we can see the data flow to x as declared in the model. Following the tree from x to its
leaves leads to the conclusion that x has indeed received two inconsistent values, and it gives insight
into how those values came to be assigned to x (0 directly and 1 via y).
One more before we move on to entities:
1x = y
2y = z
3z = x
4
5x = 0
6z = u
7u = 1
1z
2EQUIVALENT TO {x, y, z} DUE TO STATEMENTS:
3 `x = y` AT ./assignment-loop.cf:1
4 `y = z` AT ./assignment-loop.cf:2
5 `z = x` AT ./assignment-loop.cf:3
6├── u
7│ SET BY `z = u`
8│ AT ./assignment-loop.cf:6
9│ └── 1
10│ SET BY `u = 1`
11│ AT ./assignment-loop.cf:7
12└── 0
13 SET BY `x = 0`
14 AT ./assignment-loop.cf:5
This model defines an assignment loop between x, y and z. Assignment to either of these variables
will result in a flow of data to all of them. In other words, the variables are equivalent. The data trace
shows this information at lines 2–5 along with the statements that caused the equivalence. The rest of the
trace is similar to before, except that the tree now shows all assignments to any of the three variables part
of the equivalence. The tree now no longer shows just the data flow to x but to the equivalence as a whole,
since any data that flows to the equivalence will also flow to x.
1entity A:
2 number n
3end
4
5implement A using std::none
6
7x = A(n = 0)
8
9template = x
10
11y = A(n = template.n)
12y.n = 1
1attribute n on __config__::A instance
2SUBTREE for __config__::A instance:
3 CONSTRUCTED BY `A(n=template.n)`
4 AT ./entities.cf:11
5├── template.n
6│ SET BY `A(n=template.n)`
7│ AT ./entities.cf:11
8│ SUBTREE for template:
9│ └── x
10│ SET BY `template = x`
11│ AT ./entities.cf:9
12│ └── __config__::A instance
13│ SET BY `x = A(n=0)`
14│ AT ./entities.cf:7
15│ CONSTRUCTED BY `A(n=0)`
16│ AT ./entities.cf:7
17│ └── 0
18│ SET BY `A(n=0)`
19│ AT ./entities.cf:7
20└── 1
21 SET BY `y.n = 1`
22 AT ./entities.cf:12
As usual, line 1 states the variable that represents
the root of the data flow tree. In this case it’s the attribute n of an instance of A. Which instance?
That is shown in the subtree for that instance on lines 2–4. In this case it’s a very simple subtree that shows
just the construction of the instance and the line number in the configuration model. The tree for the attribute
starts at line 5. The first branch shows the assignment to template.n in the constructor for y. Then
another subtree is shown at lines 8–16, this one more useful. It shows a data flow graph like we’re used to
by now, with template as the root. Then at line 17 the trace shows the data flow template.n <- 0 referring
to entities.cf:7. This line doesn’t assign to template.n directly, but it does assign to the instance at the
end of the subtree for template (the data that flows to template).
Let’s have a look at an implementation:
1entity A:
2 number n
3end
4
5implement A using i
6
7implementation i for A:
8 self.n = 42
9end
10
11x = A(n = 0)
1attribute n on __config__::A instance
2SUBTREE for __config__::A instance:
3 CONSTRUCTED BY `A(n=0)`
4 AT ./implementation.cf:11
5├── 0
6│ SET BY `A(n=0)`
7│ AT ./implementation.cf:11
8└── 42
9 SET BY `self.n = 42`
10 AT ./implementation.cf:8
11 IN IMPLEMENTATION WITH self = __config__::A instance
12 CONSTRUCTED BY `A(n=0)`
13 AT ./implementation.cf:11
The only thing new in this trace can be found at lines 11—13. It highlights that a statement was executed within a dynamic context
and shows a subtree for the self variable.
And finally, an index:
1entity A:
2 number n
3 number m
4end
5
6index A(n)
7
8implement A using std::none
9
10A(n = 42, m = 0)
11A(n = 42, m = 1)
1attribute m on __config__::A instance
2SUBTREE for __config__::A instance:
3 CONSTRUCTED BY `A(n=42,m=0)`
4 AT ./index.cf:10
5
6 INDEX MATCH: `__config__::A instance`
7 CONSTRUCTED BY `A(n=42,m=1)`
8 AT ./index.cf:11
9├── 1
10│ SET BY `A(n=42,m=1)`
11│ AT ./index.cf:11
12└── 0
13 SET BY `A(n=42,m=0)`
14 AT ./index.cf:10
This data trace highlights the index match between the two constructors at lines 6–8.
Root cause analysis¶
Enabling the data trace also enables a root cause analysis when multiple attributes have not received a value. For example, compiling the model below results in three errors, one for each of the instances.
1entity A:
2 number n
3end
4
5implement A using std::none
6
7x = A()
8y = A()
9z = A()
10
11x.n = y.n
12y.n = z.n
1Reported 3 errors
2error 0:
3 The object __config__::A (instantiated at ./main.cf:7) is not complete: attribute n (./main.cf:2) is not set
4error 1:
5 The object __config__::A (instantiated at ./main.cf:9) is not complete: attribute n (./main.cf:2) is not set
6error 2:
7 The object __config__::A (instantiated at ./main.cf:8) is not complete: attribute n (./main.cf:2) is not set
Compiling with data trace enabled will do a root cause analysis on these errors. In this case it will infer that x.n
and y.n are only unset because z.n is unset. Compiling then shows:
1Reported 1 errors
2error 0:
3 The object __config__::A (instantiated at ./main.cf:9) is not complete: attribute n (./main.cf:2) is not set
In cases where a single error leads to errors for a collection of related attributes, this can greatly simplify the debugging process.
Usage example¶
Let’s have a look at the model below:
1entity Port:
2 string host
3 number portn
4end
5
6index Port(host, portn)
7
8entity Service:
9 string name
10 string host
11 number portn
12end
13
14Service.port [0:1] -- Port.service [0:1]
15
16
17implement Port using std::none
18implement Service using bind_port
19
20
21implementation bind_port for Service:
22 self.port = Port(host = self.host, portn = self.portn)
23end
24
25
26sshd = Service(
27 name = "opensshd",
28 host = "my_host",
29 portn = 22,
30)
31
32
33custom_service = Service(
34 name = "some_custom_service",
35 host = "my_host",
36 portn = 22,
37)
Compiling this with data trace disabled outputs the following error:
Could not set attribute `port` on instance `__config__::Service (instantiated at ./service.cf:33)` (reported in self.port = Construct(Port) (./service.cf:22))
caused by:
Could not set attribute `service` on instance `__config__::Port (instantiated at ./service.cf:22,./service.cf:22)` (reported in __config__::Port (instantiated at ./service.cf:22,./service.cf:22) (./service.cf:22))
caused by:
value set twice:
old value: __config__::Service (instantiated at ./service.cf:26)
set at ./service.cf:22
new value: __config__::Service (instantiated at ./service.cf:33)
set at ./service.cf:22
(reported in self.port = Construct(Port) (./service.cf:22))
The error message refers to service.cf:22 which is part of an implementation. It is not clear
which Service instance is being refined, which makes finding the cause of the error challenging.
Enabling data trace results in the trace below:
1attribute service on __config__::Port instance
2SUBTREE for __config__::Port instance:
3 CONSTRUCTED BY `Port(host=self.host,portn=self.portn)`
4 AT ./service.cf:22
5 IN IMPLEMENTATION WITH self = __config__::Service instance
6 CONSTRUCTED BY `Service(name='opensshd',host='my_host',portn=22)`
7 AT ./service.cf:26
8
9 INDEX MATCH: `__config__::Port instance`
10 CONSTRUCTED BY `Port(host=self.host,portn=self.portn)`
11 AT ./service.cf:22
12 IN IMPLEMENTATION WITH self = __config__::Service instance
13 CONSTRUCTED BY `Service(name='some_custom_service',host='my_host',portn=22)`
14 AT ./service.cf:33
15├── __config__::Service instance
16│ SET BY `self.port = Port(host=self.host,portn=self.portn)`
17│ AT ./service.cf:22
18│ IN IMPLEMENTATION WITH self = __config__::Service instance
19│ CONSTRUCTED BY `Service(name='some_custom_service',host='my_host',portn=22)`
20│ AT ./service.cf:33
21│ CONSTRUCTED BY `Service(name='some_custom_service',host='my_host',portn=22)`
22│ AT ./service.cf:33
23└── __config__::Service instance
24 SET BY `self.port = Port(host=self.host,portn=self.portn)`
25 AT ./service.cf:22
26 IN IMPLEMENTATION WITH self = __config__::Service instance
27 CONSTRUCTED BY `Service(name='opensshd',host='my_host',portn=22)`
28 AT ./service.cf:26
29 CONSTRUCTED BY `Service(name='opensshd',host='my_host',portn=22)`
30 AT ./service.cf:26
At lines 15 and 23 it shows the two Service instances that are also mentioned in the original error
message. This time, the dynamic implementation context is mentioned and it’s clear that these instances
have been assigned in a refinement for the Service instances constructed at lines 26 and 33 in the
configuration model respectively.
Lines 2–14 in the trace give some additional information about the
Port instance. It indicates there is an index match between the Port instances constructed in the
implementations for both Service instances. This illustrates the existence of the two branches at lines
15 and 23, and why the assignment in this implementation
resulted in the exceeding of the relation arity: the right hand side is the same instance in both cases.
Graphic visualization¶
Warning
This representation is not as complete as the data trace explained above. It does not show information about statements responsible for each assignment. It was primarily developed as an aid in developing the data flow framework on which the data trace and the root cause analysis tools are built. It’s described here because it’s closely related to the two tools described above. Its actual use in model debugging might be limited.
Note
Using this feature requires one of inmanta’s optional dependencies to be installed: pip install inmanta[dataflow_graphic].
It also requires the fdp command to be available on your system. This is most likely packaged in your distribution’s
graphviz package.
Let’s compile the model in service.cf again, this time with --experimental-dataflow-graphic.
The compile results in an error, as usual, but this time it’s accompanied by a graphic visualization of the data flow.
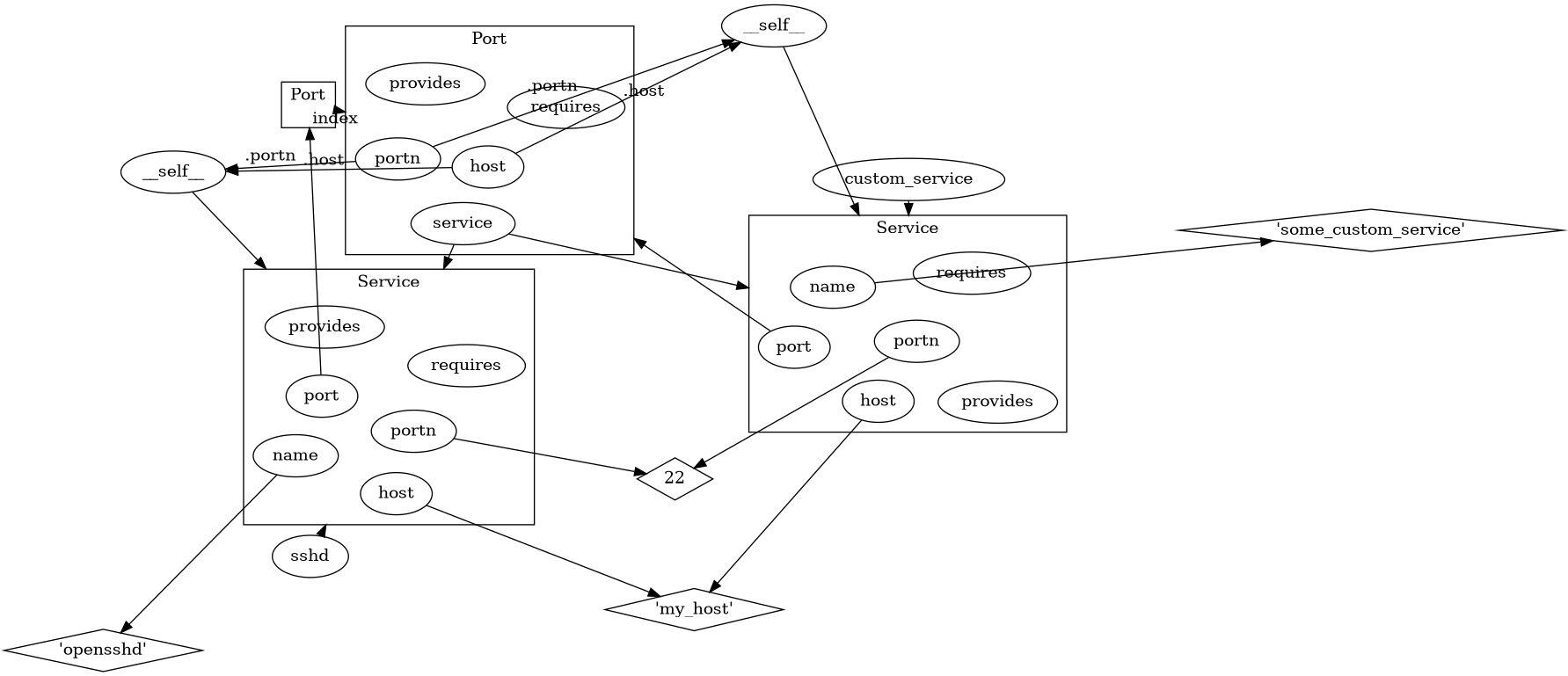
It shows all assignments, as well as the index match between the two Port constructions. An assignment where the right hand side is an
attribute x.y is shown by an arrow to x, labeled with .y. Variables are represented by ellipses, values by diamonds and instances
by rectangular containers.