HA setup¶
This page describes how to deploy an Inmanta server in a HA setup and how to perform a failover when required.
Choosing the right type of availability requires carefull consideration of various trade-offs. The orchestrator is not part of the datapath. When it is not running it will not affect the services in the network, it only affects the ability to make changes in the network. This means that the main consideration for choosing the right type of availability comes from how users interact with the web console and/or the APIs.
The Inmanta server stores its state in a PostgreSQL database and can recover entirely after a restart of the orchestrator processes based on the state in the database. As such, the PostgreSQL database should be deployed in an available setup, to ensure the durability of the state of the Inmanta Orchestrator. However, high availability is not a strict requirement.
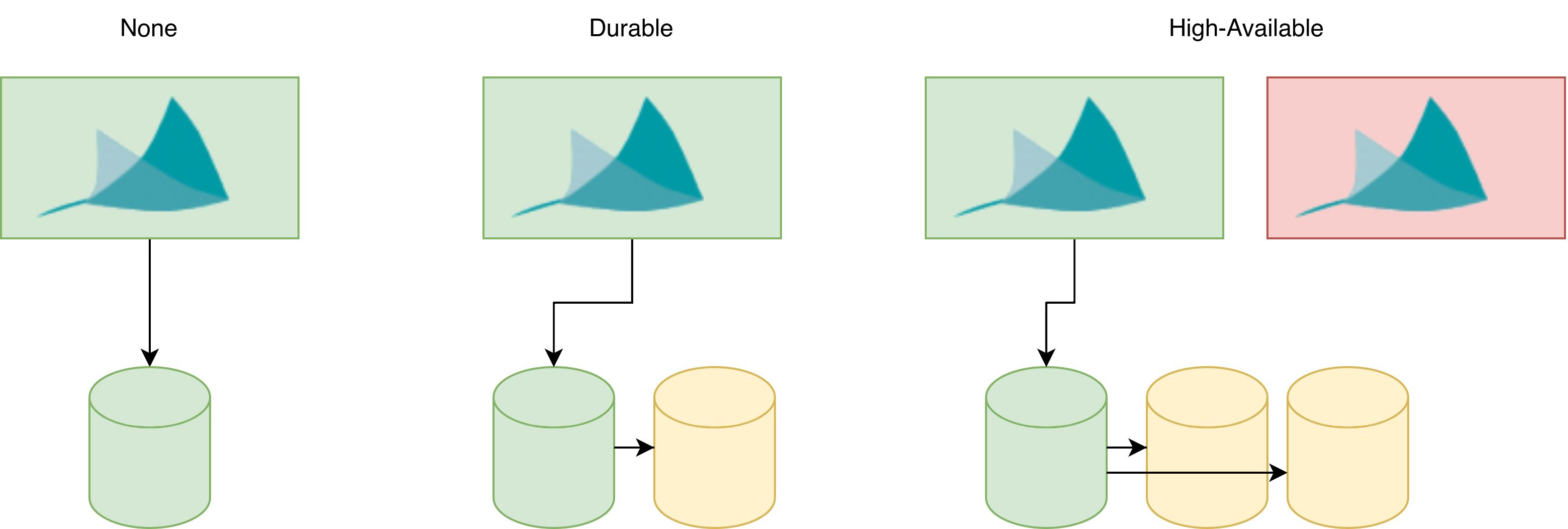
The three types of availability¶
There are three types of availability possible:
None: in case of failure the entire intent can be lost. It can only be restored by giving the orchestrator the same intent and let it step through the lifeycle of each service in its service inventory. The deployment consists of a single orchestrator instance and a single database. These can run on the same or different machines.
Durable: in case of failure the orchestrator no data is lost, however the API of the orchestrator is not available. The deployment consists of a single orchestrator instance that connects to a primary PostgreSQL database. This primary streams all changes to a standby PostgreSQL server. Database transactions only return when both databases have stored the changes durable. Depending on the deployment the failover can be done manually or fully automated.
High-available: in case of failure no data is lost and only during the failover the APIs might be unavailable for a few seconds. This deployment consists of an active orchestrator and a standby orchestrator instance. The standby instance is inactive and activates only when there is no active orchestrator. Both connect to a PostgreSQL cluster with at least 3 nodes. Database transactions only return when at least 2 out of 3 databases have stored the change durable. Depending on the deployment the failover can be done manually or fully automated.
Durable availability provides for almost all types of deployments a good trade-off between setup and operational complexity and the availability and durability guarantees. This setup has a number of properties:
It ensure durability by only returning operations like API calls when both database instances has confirmed that the changes have been stored on disk.
It is possible to use a tool such as pgpool to loadbalance read-only database queries to the standby node. However, this is out of scope of this manual.
It does not provide any additionaly availability, it even slighly reduces it: both database servers need to be up and responsive to process write queries. If the standby node is down, the master node will block on any write query. Read queries continue to be served until the database pool is exhausted.
If both durability and higher availability are required, a setup with at least 3 databases is required. This is out of scope for this documentation. Please contact support for assistance on this topic.
Setup a HA PostgreSQL cluster¶
This page describes how to setup a two node PosgreSQL cluster, consisting of a master node and a warm standby. The master node performs synchronous replication to the standby node. When the master node fails, the standby can be promoted to the new master node by performing a manual action.
Prerequisites¶
Configure the master node¶
Login on the master node and perform the following changes in the /var/lib/pgsql/data/postgresql.conf file:
# Adjust the listen address as such that the standby node
# can connect to the master node.
listen_addresses = '*'
# Increase the wal_level to the required level for data replication
wal_level = replica
# Only report success to the client when the transaction has been
# flushed to permanent storage
synchronous_commit = on
# Force synchronous replication to the standby node. The application_name
# uniquely identifies the standby instance and can be freely chosen as long
# as it only consists of printable ASCII characters.
synchronous_standby_names = 'inmanta'
# Make sure that no queries can be executed on the standby
# node while it is in recovery mode.
hot_standby = off
Execute the commands mentioned below on the master node. These commands do two thing:
They create a replication user with replication and login privileges. The standby node will use this user to connect to the master node.
They create a new replication slot, named replication. This replication slot will make sure that sufficient data is retained on the master node to synchronize the standby node with the master node.
$ sudo su - postgres -c 'psql'
$ CREATE USER replication WITH REPLICATION LOGIN PASSWORD '<password-replication-user>';
$ SELECT * FROM pg_create_physical_replication_slot('replication');
$ \q
Add the lines mentioned below to the /var/lib/pgsql/data/pg_hba.conf file. This will make sure that
the replication user can be used to setup a replication connection from the standby node to the master. Since, the standby
node can become the master node, both hosts should be add to the file.
host replication replication <ip-master-node>/32 md5
host replication replication <ip-standby-node>/32 md5
Restart the postgresql service to activate the configuration changes.
$ sudo systemctl restart postgresql
Configure the standby node¶
The standby gets configured by creating a backup of the master node and restoring it on the standby node. The commands mentioned
below create a backup in the /tmp/backup directory. This command will prompt for the password of the replication user. By
setting the -R option, a standby.signal and a postgresql.auto.conf file will be added to the backup. The presence of
the former will make the PostgreSQL server start as a standby. The latter contains replication-specific configuration settings.
Those will be processed after the postgresql.conf file is processed.
$ sudo su - postgres -c 'pg_basebackup -h <ip-master-node> -U replication -X stream -R -D /tmp/backup -S replication -W'
On the standby node, clear the content of the /var/lib/pgsql/data directory and replace it with
the content of the backup created on the master node. The postgresql.auto.conf file needs to be adjusted as such that it has the
application_name parameter in the primary_conninfo setting. This application_name should match the name
configured in the synchronous_standby_names setting of the
postgresql.conf file of the master node.
primary_conninfo = 'user=replication password=<password> channel_binding=prefer host=<password> port=5432 sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=any application_name=inmanta'
primary_slot_name = 'replication'
Comment out, the synchronous_standby_names setting in the postgresql.conf file of the standby node. This will ensure
that the standby node acts fully independently when it is promoted to a master node. Finally, start and enable the PostgreSQL
service on the standby node.
$ sudo systemctl start postgresql
$ sudo systemctl enable postgresql
Monitoring¶
This setup requires both database to be up to be up and functional. It is highly recommended to monitor this the availability of the database and the replication status. For most monitoring systems (such as nagios/icinga or promotheus/alertmanager) there are plugins avilable to do this in an efficient manner.
Failover PostgreSQL¶
This section describes the action required to recover from a failed PostgreSQL master node.
Promote a standby node to the new master node¶
When the master node fails, the standby node can be promoted to become the new master node. After this failover, the new master will acts as a fully independent instance, i.e. no replication will happen to a standby instance.
Execute the following command on the standby instance to promote it to a new master node:
$ sudo su - postgres -c 'pg_ctl promote -D /var/lib/pgsql/data/'
This command will remove the standby.signal file. It’s also recommended to cleanup the postgresql.auto.conf file
by executing the following commands:
$ sudo rm -f /var/lib/pgsql/data/postgresql.auto.conf
$ sudo systemctl reload postgresql
The old master node can be reconfigured to become the new standby node, by executing the step described in the next section.
Add a standby node to a newly promoted master node¶
This section explains how a standby can be add to a master node, which was created from a promoted standby node.
First, add a replication slot on the new master node by executing following commands:
$ sudo su - postgres -c 'psql'
$ SELECT * FROM pg_create_physical_replication_slot('replication');
$ \q
Then, configure the new standby instance by following the step mentioned in Configure the standby node.
When the standby is up, the master node perform asynchronous replication to the standby node. The master node needs to be
reconfigured to perform synchronous replication. This is done by adding the line mentioned below the postgresql.conf file
of the master node. The application_name has to match the application_name set in the postgresql.auto.conf file of the standby node.
synchronous_standby_names = 'inmanta'
Finally, reload the configuration of the master node using the following command:
$ sudo systemctl reload postgresql
Failover an Inmanta server¶
This section describes different ways to failover an Inmanta server.
Failover an Inmanta server to the warm standby PostgreSQL instance¶
This section describes how to failover an Inmanta server to a new PostgreSQL master node when the previous master node has failed.
First, stop the orchestrator by stopping the inmanta-server service.
$ sudo systemctl stop inmanta-server
Promote the standby node to a master node by following the procedure mentioned in Section Promote a standby node to the new master node.
When the promotion is finished, the Inmanta server can be reconfigured to start using the new master node. Do this by
adjusting database.host setting the /etc/inmanta/inmanta.d/database.cfg file:
[database]
host=<ip-address-new-master-node>
name=inmanta
username=inmanta
password=<password>
Now, start the Inmanta orchestrator again:
$ sudo systemctl start inmanta-server
Start a new orchestrator on warm standby PostgreSQL instance¶
This section describes what should be done to recover when the Inmanta server and the PostgreSQL master node fail simultaneously. It is also possible to failover the Inmanta server when the PostgreSQL master node has not failed.
Before starting the failover process, it’s important to ensure that the original Inmanta server is fully disabled. This is
required to prevent the situation where two orchestrators are performing configuration changes on the same infrastructure
simultaneously. Disabling the Inmanta orchestrator can be done by stopping the machine running the Inmanta server or
disabling the inmanta-server service using the following commands:
$ sudo systemctl stop inmanta-server
$ sudo systemctl disable inmanta-server
The following step should only be executed when the PostgreSQL master node has failed.
Next, promote the standby PostgreSQL node to the new master node using the procedure in Section
Promote a standby node to the new master node. When the (new) master node is up, a new Inmanta server can be installed according the
procedure mention in the Install Inmanta section. In the /etc/inmanta/inmanta.d/database.cfg configuration file,
the database.host setting should contain the IP address of the new PostgreSQL master node.
When the Inmanta server is up and running, a recompile should be done for each existing configuration model.